Eleventh competition following Youhan Lee's curriculum. Natural language processing competition.
Spooky Author Identification
Share code and discuss insights to identify horror authors from their writings
www.kaggle.com
First Kernel: Spooky NLP and Topic Modelling tutorial
- Topic modeling: the process in which we try uncover abstract themes or "topics" based on the underlying documents and words in a corpus of text
- Two standard topic modeling techniques:
- Latent Dirichlet Allocation (LDA)
- Non-negative Matrix Factorization (NMF)
Insight / Summary:
1. Top 50 (Uncleaned) Word Frequency in Training set
all_words = train['text'].str.split(expand=True).unstack().value_counts()
data = [go.Bar(
x = all_words.index.values[2:50],
y = all_words.values[2:50],
marker= dict(colorscale='Jet',
color = all_words.values[2:100]
),
text='Word counts'
)]
layout = go.Layout(
title='Top 50 (Uncleaned) Word frequencies in the training dataset'
)
fig = go.Figure(data=data, layout=layout)
py.iplot(fig, filename='basic-bar')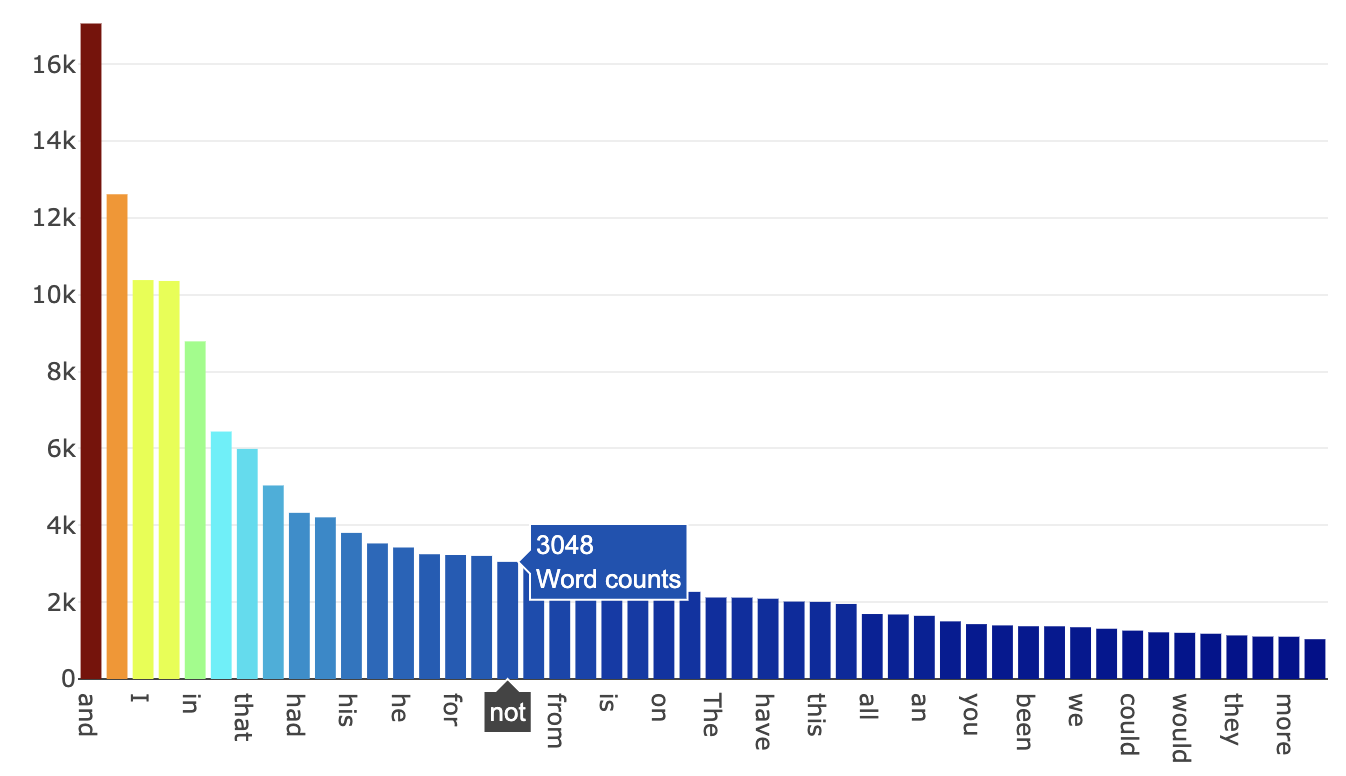
- These words are all so commonly occuring words which you could find just anywhere else. Not just in spooky stories and novels by our three authors but also in newspapers, kid book, religious texts - really almost every other english text.
- Therefore we must find some way to preprocess our dataset first to strip out all these commonly occurring words which do not bring much to the table.
2. WordClouds to visualise each author's work
- One very handy visualization tool for a data scientist when it comes to any sort of natural language processing is plotting "Word Cloud".
- A word cloud (as the name suggests) is an image that is made up of a mixture of distinct words which may make up a text or book and where the size of each word is proportional to its word frequency in that text (number of times the word appears).
- Here instead of dealing with an actual book or text, our words can simply be taken from the column "text"
1) Store the text of each author in a Python list
eap = train[train.author=="EAP"]["text"].values
hpl = train[train.author=="HPL"]["text"].values
mws = train[train.author=="MWS"]["text"].values2) Encoding image and imported
from wordcloud import WordCloud, STOPWORDS- Generating a normal wordcloud is rather boring so I would like to introduce to you a technique of importing pictures (something relevant) and using the outline of that picture as a mask for our wordclouds.
- Therefore the pictures that I have chosen are the ones I feel most representative for their authors:
- The Raven for Edgar Allen Poe
- Octopus Cthulu-thingy for HP Lovecraft
- Frankenstein for Mary Shelly
- The way I am loading in the pictures on Kaggle is a sort of a feature hack although readers familiar to my work know this trick.
- I first derive the Base64 encoding of whatever images I want to use and then use that particular encoding and re-convert the picture back on the notebook.
3) Decoding image using codecs module
import codecs
# Generate the Mask for EAP
f1 = open("eap.png", "wb")
f1.write(codecs.decode(eap_64,'base64'))
f1.close()
img1 = imread("eap.png")
# img = img.resize((980,1080))
hcmask = img1
f2 = open("mws.png", "wb")
f2.write(codecs.decode(mws_64,'base64'))
f2.close()
img2 = imread("mws.png")
hcmask2 = img2
f3 = open("hpl.png", "wb")
f3.write(codecs.decode(hpl_64,'base64'))
f3.close()
img3 = imread("hpl.png")
hcmask3 = img3;4) Finally wordcloud
# The wordcloud of Cthulhu/squidy thing for HP Lovecraft
plt.figure(figsize=(16,13))
wc = WordCloud(background_color="black", max_words=10000,
mask=hcmask3, stopwords=STOPWORDS, max_font_size= 40)
wc.generate(" ".join(hpl))
plt.title("HP Lovecraft (Cthulhu-Squidy)", fontsize=20)
# plt.imshow(wc.recolor( colormap= 'Pastel1_r' , random_state=17), alpha=0.98)
plt.imshow(wc.recolor( colormap= 'Pastel2' , random_state=17), alpha=0.98)
plt.axis('off')
3. Text preprocessing
- Tokenization - Segregation of the text into its individual constitutent words.
- Stopwords - Throw away any words that occur too frequently as its frequency of occurrence will not be useful in helping detecting relevant texts. (as an aside also consider throwing away words that occur very infrequently).
- Stemming - combine variants of words into a single parent word that still conveys the same meaning
- Vectorization - Converting text into vector format. One of the simplest is the famous bag-of-words approach, where you create a matrix (for each document or text in the corpus). In the simplest form, this matrix stores word frequencies (word counts) and is often referred to as vectorization of the raw text.
4. Tokenization using NLTK module
- The concept of tokenization is the act of taking a sequence of characters (think of Python strings) in a given document and dicing it up into its individual constituent pieces, which are the eponymous "tokens" of this method.
- One could loosely think of them as singular words in a sentence. One could naively implement the "split( )" method on a string which separates it into a python list based on the identifier in the argument. It is actually not that trivial to.
- Here we split the first sentence of the text in the training data just on a space as follows:
# Storing the first text element as a string
first_text = train.text.values[0]
print(first_text)
print("="*90)
print(first_text.split(" "))
- However as you can see from this first attempt at tokenization, the segregation(분리) of the sentence into its individual elements (or terms) is not entirely accurate.
- As an example, look at the second element of the list which contains the term "process,".
- The punctuation mark (comma) has also been included and is being treated along with the word "process" as a term in itself.
- Ideally we would like the comma and the word to be in two different and separate elements of the list.
- Trying to do this with pure python list operations will be quite complex so this is where the NLTK library comes into play.
- There is a convenient method "word_tokenize( )" (TreebankWord tokenizer) which strips out singular words as well as punctuations into separate elements automatically as follows:
first_text_list = nltk.word_tokenize(first_text)
print(first_text_list)
5. Stopword Removal
- As alluded to above stopwords are generally words that appear so commonly and at such a high frequency in the corpus that they don't actually contribute much to the learning or predictive process as a learning model would fail to distinguish it from other texts.
- Stopwords include terms such as "to" or "the" and therefore, it would be to our benefit to remove them during the pre-processing phase.
- Conveniently, NLTK comes with a predefined list of 153 english stopwords.
stopwords = nltk.corpus.stopwords.words('english')
len(stopwords)
# result: 179
Filtering out stopwords from our tokenized list of words:
first_text_list_cleaned = [word for word in first_text_list if word.lower() not in stopwords]
print(first_text_list_cleaned)
print("="*90)
print("Length of original list: {0} words\n"
"Length of list after stopwords removal: {1} words"
.format(len(first_text_list), len(first_text_list_cleaned)))
6. Stemming and Lemmatization
- The work at this stage attempts to reduce as many different variations of similar words into a single term ( different branches all reduced to single word stem).
- Therefore if we have "running", "runs" and "run", you would really want these three distinct words to collapse into just the word "run". (However of course you lose granularity of the past, present or future tense).
- We can turn to NLTK again which provides various stemmers which include variants such as the Porter stemming algorithm, the lancaster stemmer and the Snowball stemmer.
- In the following example, I will create a porter stemmer instance as follows:
stemmer = nltk.stem.PorterStemmer()print("The stemmed form of running is: {}".format(stemmer.stem("running")))
print("The stemmed form of runs is: {}".format(stemmer.stem("runs")))
print("The stemmed form of run is: {}".format(stemmer.stem("run")))
# The stemmed form of running is: run
# The stemmed form of runs is: run
# The stemmed form of run is: run- As we can see, the stemmer has successfully reduced the given words above into a base form and this will be most in helping us reduce the size of our dataset of words when we come to learning and classification tasks.
- However there is one flaw with stemming and that is the fact that the process involves quite a crude heuristic in chopping off the ends of words in the hope of reducing a particular word into a human recognizable base form.
- Therefore this process does not take into account vocabulary or word forms when collapsing words as this example will illustrate:
print("The stemmed form of leaves is: {}".format(stemmer.stem("leaves")))
# result: The stemmed form of leaves is: leav
Lemmatization
- Therefore we turn to another that we could use in lieu of stemming.
- This method is called lemmatization which aims to achieve the same effect as the former method.
- However unlike a stemmer, lemmatizing the dataset aims to reduce words based on an actual dictionary or vocabulary (the Lemma) and therefore will not chop off words into stemmed forms that do not carry any lexical meaning.
- Here we can utilize NLTK once again to initialize a lemmatizer (WordNet variant) and inspect how it collapses words as follows:
from nltk.stem import WordNetLemmatizer
lemm = WordNetLemmatizer()
print("The lemmatized form of leaves is: {}".format(lemm.lemmatize("leaves")))
# result: The lemmatized form of leaves is: leaf
7. Vectorizing Raw Text
- In the vast collection of NLP literature, there are many different purposes for analyzing raw text, where in some cases you would like to compare the similarity of one body of text to another (Clustering techniques/Distance measurements), text classification (the purpose of this competition) as well as uncovering the topics that comprise a body of text (the aim of this notebook).
- With the purpose of uncovering topics at the back of our minds we must now think of how to feed the raw text into a machine learning model.
- Having already discussed tokenization, stopword removals and stemming (or maybe lemmatizing) we have now arrived at a reasonably cleaner text dataset then we started out with.
- However at this juncture, our raw text though human readable is still unfortunately not yet machine readable.
- A machine can read in bits and numbers and therefore we will first need to convert our text into numbers for which we utilise a very common approach known as the Bag-of-Words
The Bag of Words approach
- This approach uses the counts of words as a starting block and records the occurrence of each word (from the entire text) in a vector specific to that particular word.
- For example given these two sentences "I love to eat Burgers", "I love to eat Fries", we first tokenize to obtain our vocabulary of 6 words from which we can get the word counts for - [I, love, to, eat, Burgers, Fries].
- Vectorizing the text via the Bag of Words approach, we get six distinct vectors one for each word.
- So you ask since we now have rows consisting of numbers (instead of text) what forms the columns (or features)?
- Well each word now becomes an individual feature/column in this new transformed dataset.
- To illustrate this point, I shall utilize the Scikit-learn library to implement a vectorizer that generates a vector of word counts (term frequencies) - via the CountVectorizer method as follows.
# Defining our sentence
sentence = ["I love to eat Burgers",
"I love to eat Fries"]
vectorizer = CountVectorizer(min_df=0)
sentence_transform = vectorizer.fit_transform(sentence)
Fitting the vectorizer to the dataset
- Here we initialize and create a simple term frequency object via the CountVectorizer function simply called "vectorizer".
- The parameters that I have provided explicitly (the rest are left as default) are the bare minimum.
- Here "min_df" in the parameter refers to the minimum document frequency and the vectorizer will simply drop all words that occur less than that value set (either integer or in fraction form).
- Finally we apply the fit_transform method is actually comprised of two steps.
- The first step is the fit method where the vectorizer is mapped to the dataset that you provide.
- Once this is done, the actual vectorizing operation is performed via the transform method where the raw text is turned into its vector form as shown below:
print("The features are:\n {}".format(vectorizer.get_feature_names()))
print("\nThe vectorized array looks like:\n {}".format(sentence_transform.toarray()))

Sparse matrix vector ouptuts
- From the output of the vectorized text, we can see that the features consist of the words in the corpus of text that we fed into the vectorizer (here the corpus being the two sentences we defined earlier).
- Simply call the get_feature_names attribute from the vectorizer to inspect it.
- With regards to the transformed text, one would be tempted to inspect the values by simplying calling it.
- However when you try to call it you really just get a message which states "sparse matrix of type class 'numpy.int64' with 8 stored elements in Compressed Sparse Row format".
- Therefore this means that the vectorizer returns the transformed raw text as a matrix where most of its values are zero or almost negligible, hence the term sparse.
- Thinking about this, it does make sense that our returned matrices contain quite a high degree of sparsity due to the fact that most words in a language appear relatively infrequently in any given text.
8. Topic modeling
- Latent Dirichlet Allocation - Probabilistic, generative model which uncovers the topics latent to a dataset by assigning weights to words in a corpus, where each topic will assign different probability weights to each word.
- Non-negative Matrix Factorization - Approximation method that takes an input matrix and approximates the factorization of this matrix into two other matrices, with the caveat that the values in the matrix be non-negative.
- When you vectorize the raw text with CountVectorizer, the dual stages of tokenizing and stopwords filtering are automatically included as a high-level component.
- Here unlike the NLTK tokenizer that you were introduced to in the Section 2a earlier, Sklearn's tokenizer discards all single character terms like ('a', 'w' etc) and also lower cases all terms by default.
- Filtering out stopwords in Sklearn is as convenient as passing the value 'english' into the argument "stop_words" where a built-in English stopword list is automatically used.
- Unfortunately, there is no built-in lemmatizer in the vectorizer so we are left with a couple of options.
- Either implementing it separately everytime before feeding the data for vectorizing or somehow extend the sklearn implementation to include this functionality.
- Luckily for us, we have the latter option where we can extend the CountVectorizer class by overwriting the "build_analyzer" method as follows:
lemm = WordNetLemmatizer()
class LemmaCountVectorizer(CountVectorizer):
def build_analyzer(self):
analyzer = super(LemmaCountVectorizer, self).build_analyzer()
return lambda doc: (lemm.lemmatize(w) for w in analyzer(doc))# Storing the entire training text in a list
text = list(train.text.values)
# Calling our overwritten Count vectorizer
tf_vectorizer = LemmaCountVectorizer(max_df=0.95,
min_df=2,
stop_words='english',
decode_error='ignore')
tf = tf_vectorizer.fit_transform(text)
Latent Dirichlet Allocation
- There are a couple of different implements of this LDA algorithm but in this notebook, I will be using Sklearn's implementation.
- Another very well-known LDA implementation is Radim Rehurek's gensim, so check it out as well.
- In LDA, the modelling process revolves around three things: the text corpus, its collection of documents, D and the words W in the documents.
- Therefore the algorithm attempts to uncover K topics from this corpus via the following way (illustrated by the diagram).

- Model each topic, $\kappa$ via a Dirichlet prior distribution given by $\beta_{k}$:
- Model each document d by another Dirichlet distribution parameterized by $\alpha$:
- Subsequently for document d, we generate a topic via a multinomial distribution which we then backtrack and use to generate the correspondings words related to that topic via another multinomial distribution:
- The LDA algorithm first models documents via a mixture model of topics.
- From these topics, words are then assigned weights based on the probability distribution of these topics.
- It is this probabilistic assignment over words that allow a user of LDA to say how likely a particular word falls into a topic.
- Subsequently from the collection of words assigned to a particular topic, are we thus able to gain an insight as to what that topic may actually represent from a lexical point of view.
- From a standard LDA model, there are really a few key parameters that we have to keep in mind and consider programmatically tuning before we invoke the model:
- n_components: The number of topics that you specify to the model
- $\alpha$ parameter: This is the dirichlet parameter that can be linked to the document topic prior
- $\beta$ parameter: This is the dirichlet parameter linked to the topic word prior
- To invoke the algorithm, we simply create an LDA instance through the Sklearn's LatentDirichletAllocation function.
- The various parameters would ideally have been obtained through some sort of validation scheme.
- In this instance, the optimal value of n_components (or topic number) was found by conducting a KMeans + Latent Semantic Analysis(LSA) Scheme (as shown in this paper here) whereby the number of Kmeans clusters and number of LSA dimensions were iterated through and the best silhouette mean score.
lda = LatentDirichletAllocation(n_components=11, max_iter=5,
learning_method = 'online',
learning_offset = 50.,
random_state = 0)
lda.fit(tf)
Second Kernel: Approaching (Almost) Any NLP Problem on Kaggle
- Trying out various modeling techniques:
- tfidf
- count features
- logistic regression
- naive bayes
- svm
- xgboost
- grid search
- word vectors
- LSTM
- GRU
- Ensembling
Insight / Summary:
1. Metric
def multiclass_logloss(actual, predicted, eps=1e-15):
"""Multi class version of Logarithmic Loss metric.
:param actual: Array containing the actual target classes
:param predicted: Matrix with class predictions, one probability per class
"""
# Convert 'actual' to a binary array if it's not already:
if len(actual.shape) == 1:
actual2 = np.zeros((actual.shape[0], predicted.shape[1]))
for i, val in enumerate(actual):
actual2[i, val] = 1
actual = actual2
clip = np.clip(predicted, eps, 1 - eps)
rows = actual.shape[0]
vsota = np.sum(actual * np.log(clip))
return -1.0 / rows * vsota- For this particular problem, Kaggle has specified multi-class log-loss as evaluation metric.
2. TF-IDF + Logistic Regression
# Always start with these features. They work (almost) everytime!
tfv = TfidfVectorizer(min_df=3, max_features=None,
strip_accents='unicode', analyzer='word',token_pattern=r'\w{1,}',
ngram_range=(1, 3), use_idf=1,smooth_idf=1,sublinear_tf=1,
stop_words = 'english')
# Fitting TF-IDF to both training and test sets (semi-supervised learning)
tfv.fit(list(xtrain) + list(xvalid))
xtrain_tfv = tfv.transform(xtrain)
xvalid_tfv = tfv.transform(xvalid)# Fitting a simple Logistic Regression on TFIDF
clf = LogisticRegression(C=1.0)
clf.fit(xtrain_tfv, ytrain)
predictions = clf.predict_proba(xvalid_tfv)
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.626
3. Word Count as feature + Logistic Regression
ctv = CountVectorizer(analyzer='word',token_pattern=r'\w{1,}',
ngram_range=(1, 3), stop_words = 'english')
# Fitting Count Vectorizer to both training and test sets (semi-supervised learning)
ctv.fit(list(xtrain) + list(xvalid))
xtrain_ctv = ctv.transform(xtrain)
xvalid_ctv = ctv.transform(xvalid)# Fitting a simple Logistic Regression on Counts
clf = LogisticRegression(C=1.0)
clf.fit(xtrain_ctv, ytrain)
predictions = clf.predict_proba(xvalid_ctv)
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.528- Instead of using TF-IDF, we can also use word counts as features.
- This can be done easily using CountVectorizer from scikit-learn.
4. Naive Bayes + TF-IDF
# Fitting a simple Naive Bayes on TFIDF
clf = MultinomialNB()
clf.fit(xtrain_tfv, ytrain)
predictions = clf.predict_proba(xvalid_tfv)
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.578
5. Naive Bayes + Word Count
# Fitting a simple Naive Bayes on Counts
clf = MultinomialNB()
clf.fit(xtrain_ctv, ytrain)
predictions = clf.predict_proba(xvalid_ctv)
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.485
6. SVM + TF-IDF
- Since SVMs take a lot of time, we will reduce the number of features from the TF-IDF using Singular Value Decomposition before applying SVM.
- Also, note that before applying SVMs, we must standardize the data.
# Apply SVD, I chose 120 components. 120-200 components are good enough for SVM model.
svd = decomposition.TruncatedSVD(n_components=120)
svd.fit(xtrain_tfv)
xtrain_svd = svd.transform(xtrain_tfv)
xvalid_svd = svd.transform(xvalid_tfv)
# Scale the data obtained from SVD. Renaming variable to reuse without scaling.
scl = preprocessing.StandardScaler()
scl.fit(xtrain_svd)
xtrain_svd_scl = scl.transform(xtrain_svd)
xvalid_svd_scl = scl.transform(xvalid_svd)# Fitting a simple SVM
clf = SVC(C=1.0, probability=True) # since we need probabilities
clf.fit(xtrain_svd_scl, ytrain)
predictions = clf.predict_proba(xvalid_svd_scl)
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.741
7. XGBoost + TF-IDF
# Fitting a simple xgboost on tf-idf
clf = xgb.XGBClassifier(max_depth=7, n_estimators=200, colsample_bytree=0.8,
subsample=0.8, nthread=10, learning_rate=0.1)
clf.fit(xtrain_tfv.tocsc(), ytrain)
predictions = clf.predict_proba(xvalid_tfv.tocsc())
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.782# Fitting a simple xgboost on tf-idf
clf = xgb.XGBClassifier(max_depth=7, n_estimators=200, colsample_bytree=0.8,
subsample=0.8, nthread=10, learning_rate=0.1)
clf.fit(xtrain_ctv.tocsc(), ytrain)
predictions = clf.predict_proba(xvalid_ctv.tocsc())
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.772# Fitting a simple xgboost on tf-idf svd features
clf = xgb.XGBClassifier(max_depth=7, n_estimators=200, colsample_bytree=0.8,
subsample=0.8, nthread=10, learning_rate=0.1)
clf.fit(xtrain_svd, ytrain)
predictions = clf.predict_proba(xvalid_svd)
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.768# Fitting a simple xgboost on tf-idf svd features
clf = xgb.XGBClassifier(nthread=10)
clf.fit(xtrain_svd, ytrain)
predictions = clf.predict_proba(xvalid_svd)
print ("logloss: %0.3f " % multiclass_logloss(yvalid, predictions))
# result: logloss: 0.816
8. Word Embedding - Using GloVe
# this function creates a normalized vector for the whole sentence
def sent2vec(s):
words = str(s).lower().decode('utf-8')
words = word_tokenize(words)
words = [w for w in words if not w in stop_words]
words = [w for w in words if w.isalpha()]
M = []
for w in words:
try:
M.append(embeddings_index[w])
except:
continue
M = np.array(M)
v = M.sum(axis=0)
if type(v) != np.ndarray:
return np.zeros(300)
return v / np.sqrt((v ** 2).sum())# create sentence vectors using the above function for training and validation set
xtrain_glove = [sent2vec(x) for x in tqdm(xtrain)]
xvalid_glove = [sent2vec(x) for x in tqdm(xvalid)]
xtrain_glove = np.array(xtrain_glove)
xvalid_glove = np.array(xvalid_glove)
9. Using Neural Network
# scale the data before any neural net:
scl = preprocessing.StandardScaler()
xtrain_glove_scl = scl.fit_transform(xtrain_glove)
xvalid_glove_scl = scl.transform(xvalid_glove)
# we need to binarize the labels for the neural net
ytrain_enc = np_utils.to_categorical(ytrain)
yvalid_enc = np_utils.to_categorical(yvalid)
# create a simple 3 layer sequential neural net
model = Sequential()
model.add(Dense(300, input_dim=300, activation='relu'))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(Dense(300, activation='relu'))
model.add(Dropout(0.3))
model.add(BatchNormalization())
model.add(Dense(3))
model.add(Activation('softmax'))
# compile the model
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.fit(xtrain_glove_scl, y=ytrain_enc, batch_size=64,
epochs=5, verbose=1,
validation_data=(xvalid_glove_scl, yvalid_enc))
10. LSTM
With LSTMs we need to tokenize the text data
# using keras tokenizer here
token = text.Tokenizer(num_words=None)
max_len = 70
token.fit_on_texts(list(xtrain) + list(xvalid))
xtrain_seq = token.texts_to_sequences(xtrain)
xvalid_seq = token.texts_to_sequences(xvalid)
# zero pad the sequences
xtrain_pad = sequence.pad_sequences(xtrain_seq, maxlen=max_len)
xvalid_pad = sequence.pad_sequences(xvalid_seq, maxlen=max_len)
word_index = token.word_index# create an embedding matrix for the words we have in the dataset
embedding_matrix = np.zeros((len(word_index) + 1, 300))
for word, i in tqdm(word_index.items()):
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector# A simple LSTM with glove embeddings and two dense layers
model = Sequential()
model.add(Embedding(len(word_index) + 1,
300,
weights=[embedding_matrix],
input_length=max_len,
trainable=False))
model.add(SpatialDropout1D(0.3))
model.add(LSTM(100, dropout=0.3, recurrent_dropout=0.3))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')model.fit(xtrain_pad, y=ytrain_enc, batch_size=512, epochs=100, verbose=1, validation_data=(xvalid_pad, yvalid_enc))
11. Version with early stopping
# A simple LSTM with glove embeddings and two dense layers
model = Sequential()
model.add(Embedding(len(word_index) + 1,
300,
weights=[embedding_matrix],
input_length=max_len,
trainable=False))
model.add(SpatialDropout1D(0.3))
model.add(LSTM(300, dropout=0.3, recurrent_dropout=0.3))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# Fit the model with early stopping callback
earlystop = EarlyStopping(monitor='val_loss', min_delta=0, patience=3, verbose=0, mode='auto')
model.fit(xtrain_pad, y=ytrain_enc, batch_size=512, epochs=100,
verbose=1, validation_data=(xvalid_pad, yvalid_enc), callbacks=[earlystop])
12. Bi-directional LSTM
# A simple bidirectional LSTM with glove embeddings and two dense layers
model = Sequential()
model.add(Embedding(len(word_index) + 1,
300,
weights=[embedding_matrix],
input_length=max_len,
trainable=False))
model.add(SpatialDropout1D(0.3))
model.add(Bidirectional(LSTM(300, dropout=0.3, recurrent_dropout=0.3)))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# Fit the model with early stopping callback
earlystop = EarlyStopping(monitor='val_loss', min_delta=0, patience=3, verbose=0, mode='auto')
model.fit(xtrain_pad, y=ytrain_enc, batch_size=512, epochs=100,
verbose=1, validation_data=(xvalid_pad, yvalid_enc), callbacks=[earlystop])
# GRU with glove embeddings and two dense layers
model = Sequential()
model.add(Embedding(len(word_index) + 1,
300,
weights=[embedding_matrix],
input_length=max_len,
trainable=False))
model.add(SpatialDropout1D(0.3))
model.add(GRU(300, dropout=0.3, recurrent_dropout=0.3, return_sequences=True))
model.add(GRU(300, dropout=0.3, recurrent_dropout=0.3))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8))
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# Fit the model with early stopping callback
earlystop = EarlyStopping(monitor='val_loss', min_delta=0, patience=3, verbose=0, mode='auto')
model.fit(xtrain_pad, y=ytrain_enc, batch_size=512, epochs=100,
verbose=1, validation_data=(xvalid_pad, yvalid_enc), callbacks=[earlystop])
14. Ensemble
# this is the main ensembling class. how to use it is in the next cell!
import numpy as np
from sklearn.metrics import roc_auc_score
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold, KFold
import pandas as pd
import os
import sys
import logging
logging.basicConfig(
level=logging.DEBUG,
format="[%(asctime)s] %(levelname)s %(message)s",
datefmt="%H:%M:%S", stream=sys.stdout)
logger = logging.getLogger(__name__)
class Ensembler(object):
def __init__(self, model_dict, num_folds=3, task_type='classification', optimize=roc_auc_score,
lower_is_better=False, save_path=None):
"""
Ensembler init function
:param model_dict: model dictionary, see README for its format
:param num_folds: the number of folds for ensembling
:param task_type: classification or regression
:param optimize: the function to optimize for, e.g. AUC, logloss, etc. Must have two arguments y_test and y_pred
:param lower_is_better: is lower value of optimization function better or higher
:param save_path: path to which model pickles will be dumped to along with generated predictions, or None
"""
self.model_dict = model_dict
self.levels = len(self.model_dict)
self.num_folds = num_folds
self.task_type = task_type
self.optimize = optimize
self.lower_is_better = lower_is_better
self.save_path = save_path
self.training_data = None
self.test_data = None
self.y = None
self.lbl_enc = None
self.y_enc = None
self.train_prediction_dict = None
self.test_prediction_dict = None
self.num_classes = None
def fit(self, training_data, y, lentrain):
"""
:param training_data: training data in tabular format
:param y: binary, multi-class or regression
:return: chain of models to be used in prediction
"""
self.training_data = training_data
self.y = y
if self.task_type == 'classification':
self.num_classes = len(np.unique(self.y))
logger.info("Found %d classes", self.num_classes)
self.lbl_enc = LabelEncoder()
self.y_enc = self.lbl_enc.fit_transform(self.y)
kf = StratifiedKFold(n_splits=self.num_folds)
train_prediction_shape = (lentrain, self.num_classes)
else:
self.num_classes = -1
self.y_enc = self.y
kf = KFold(n_splits=self.num_folds)
train_prediction_shape = (lentrain, 1)
self.train_prediction_dict = {}
for level in range(self.levels):
self.train_prediction_dict[level] = np.zeros((train_prediction_shape[0],
train_prediction_shape[1] * len(self.model_dict[level])))
for level in range(self.levels):
if level == 0:
temp_train = self.training_data
else:
temp_train = self.train_prediction_dict[level - 1]
for model_num, model in enumerate(self.model_dict[level]):
validation_scores = []
foldnum = 1
for train_index, valid_index in kf.split(self.train_prediction_dict[0], self.y_enc):
logger.info("Training Level %d Fold # %d. Model # %d", level, foldnum, model_num)
if level != 0:
l_training_data = temp_train[train_index]
l_validation_data = temp_train[valid_index]
model.fit(l_training_data, self.y_enc[train_index])
else:
l0_training_data = temp_train[0][model_num]
if type(l0_training_data) == list:
l_training_data = [x[train_index] for x in l0_training_data]
l_validation_data = [x[valid_index] for x in l0_training_data]
else:
l_training_data = l0_training_data[train_index]
l_validation_data = l0_training_data[valid_index]
model.fit(l_training_data, self.y_enc[train_index])
logger.info("Predicting Level %d. Fold # %d. Model # %d", level, foldnum, model_num)
if self.task_type == 'classification':
temp_train_predictions = model.predict_proba(l_validation_data)
self.train_prediction_dict[level][valid_index,
(model_num * self.num_classes):(model_num * self.num_classes) +
self.num_classes] = temp_train_predictions
else:
temp_train_predictions = model.predict(l_validation_data)
self.train_prediction_dict[level][valid_index, model_num] = temp_train_predictions
validation_score = self.optimize(self.y_enc[valid_index], temp_train_predictions)
validation_scores.append(validation_score)
logger.info("Level %d. Fold # %d. Model # %d. Validation Score = %f", level, foldnum, model_num,
validation_score)
foldnum += 1
avg_score = np.mean(validation_scores)
std_score = np.std(validation_scores)
logger.info("Level %d. Model # %d. Mean Score = %f. Std Dev = %f", level, model_num,
avg_score, std_score)
logger.info("Saving predictions for level # %d", level)
train_predictions_df = pd.DataFrame(self.train_prediction_dict[level])
train_predictions_df.to_csv(os.path.join(self.save_path, "train_predictions_level_" + str(level) + ".csv"),
index=False, header=None)
return self.train_prediction_dict
def predict(self, test_data, lentest):
self.test_data = test_data
if self.task_type == 'classification':
test_prediction_shape = (lentest, self.num_classes)
else:
test_prediction_shape = (lentest, 1)
self.test_prediction_dict = {}
for level in range(self.levels):
self.test_prediction_dict[level] = np.zeros((test_prediction_shape[0],
test_prediction_shape[1] * len(self.model_dict[level])))
self.test_data = test_data
for level in range(self.levels):
if level == 0:
temp_train = self.training_data
temp_test = self.test_data
else:
temp_train = self.train_prediction_dict[level - 1]
temp_test = self.test_prediction_dict[level - 1]
for model_num, model in enumerate(self.model_dict[level]):
logger.info("Training Fulldata Level %d. Model # %d", level, model_num)
if level == 0:
model.fit(temp_train[0][model_num], self.y_enc)
else:
model.fit(temp_train, self.y_enc)
logger.info("Predicting Test Level %d. Model # %d", level, model_num)
if self.task_type == 'classification':
if level == 0:
temp_test_predictions = model.predict_proba(temp_test[0][model_num])
else:
temp_test_predictions = model.predict_proba(temp_test)
self.test_prediction_dict[level][:, (model_num * self.num_classes): (model_num * self.num_classes) +
self.num_classes] = temp_test_predictions
else:
if level == 0:
temp_test_predictions = model.predict(temp_test[0][model_num])
else:
temp_test_predictions = model.predict(temp_test)
self.test_prediction_dict[level][:, model_num] = temp_test_predictions
test_predictions_df = pd.DataFrame(self.test_prediction_dict[level])
test_predictions_df.to_csv(os.path.join(self.save_path, "test_predictions_level_" + str(level) + ".csv"),
index=False, header=None)
return self.test_prediction_dict# specify the data to be used for every level of ensembling:
train_data_dict = {0: [xtrain_tfv, xtrain_ctv, xtrain_tfv, xtrain_ctv], 1: [xtrain_glove]}
test_data_dict = {0: [xvalid_tfv, xvalid_ctv, xvalid_tfv, xvalid_ctv], 1: [xvalid_glove]}
model_dict = {0: [LogisticRegression(), LogisticRegression(), MultinomialNB(alpha=0.1), MultinomialNB()],
1: [xgb.XGBClassifier(silent=True, n_estimators=120, max_depth=7)]}
ens = Ensembler(model_dict=model_dict, num_folds=3, task_type='classification',
optimize=multiclass_logloss, lower_is_better=True, save_path='')
ens.fit(train_data_dict, ytrain, lentrain=xtrain_glove.shape[0])
preds = ens.predict(test_data_dict, lentest=xvalid_glove.shape[0])Third Kernel: Simple Feature Engg Notebook - Spooky Author
- Create different features that will help us in identifying the spooky authors.
- Meta features - features that are extracted from the text like number of words, number of stop words, number of punctuations etc
- Text based features - features directly based on the text / words like frequency, svd, word2vec etc.
Insight / Summary:
1. Meta Features
- Number of words in the text
- Number of unique words in the text
- Number of characters in the text
- Number of stopwords
- Number of punctuations
- Number of upper case words
- Number of title case words
- Average length of the words
## Number of words in the text ##
train_df["num_words"] = train_df["text"].apply(lambda x: len(str(x).split()))
test_df["num_words"] = test_df["text"].apply(lambda x: len(str(x).split()))
## Number of unique words in the text ##
train_df["num_unique_words"] = train_df["text"].apply(lambda x: len(set(str(x).split())))
test_df["num_unique_words"] = test_df["text"].apply(lambda x: len(set(str(x).split())))
## Number of characters in the text ##
train_df["num_chars"] = train_df["text"].apply(lambda x: len(str(x)))
test_df["num_chars"] = test_df["text"].apply(lambda x: len(str(x)))
## Number of stopwords in the text ##
train_df["num_stopwords"] = train_df["text"].apply(lambda x: len([w for w in str(x).lower().split() if w in eng_stopwords]))
test_df["num_stopwords"] = test_df["text"].apply(lambda x: len([w for w in str(x).lower().split() if w in eng_stopwords]))
## Number of punctuations in the text ##
train_df["num_punctuations"] =train_df['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation]) )
test_df["num_punctuations"] =test_df['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation]) )
## Number of title case words in the text ##
train_df["num_words_upper"] = train_df["text"].apply(lambda x: len([w for w in str(x).split() if w.isupper()]))
test_df["num_words_upper"] = test_df["text"].apply(lambda x: len([w for w in str(x).split() if w.isupper()]))
## Number of title case words in the text ##
train_df["num_words_title"] = train_df["text"].apply(lambda x: len([w for w in str(x).split() if w.istitle()]))
test_df["num_words_title"] = test_df["text"].apply(lambda x: len([w for w in str(x).split() if w.istitle()]))
## Average length of the words in the text ##
train_df["mean_word_len"] = train_df["text"].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
test_df["mean_word_len"] = test_df["text"].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
2. Text-based features
1) tf-idf values of the words present in the text
### Fit transform the tfidf vectorizer ###
tfidf_vec = TfidfVectorizer(stop_words='english', ngram_range=(1,3))
full_tfidf = tfidf_vec.fit_transform(train_df['text'].values.tolist() + test_df['text'].values.tolist())
train_tfidf = tfidf_vec.transform(train_df['text'].values.tolist())
test_tfidf = tfidf_vec.transform(test_df['text'].values.tolist())The tfidf output is a sparse matrix and so if we have to use it with other dense features, we have couple of choices.
- We can choose to get the top 'n' features (depending on the system config) from the tfidf vectorizer, convert it into dense format and concat with other features.
- Build a model using just the sparse features and then use the predictions as one of the features along with other dense features.
- Based on the dataset, one might perform better than the other. Here we can use the second approach since there are some very good scoring kernels using all the features of tfidf.
- Also it seems that, Naive Bayes is performing better in this dataset. So we could build a naive bayes model using tfidf features as it is faster to train.
def runMNB(train_X, train_y, test_X, test_y, test_X2):
model = naive_bayes.MultinomialNB()
model.fit(train_X, train_y)
pred_test_y = model.predict_proba(test_X)
pred_test_y2 = model.predict_proba(test_X2)
return pred_test_y, pred_test_y2, modelcv_scores = []
pred_full_test = 0
pred_train = np.zeros([train_df.shape[0], 3])
kf = model_selection.KFold(n_splits=5, shuffle=True, random_state=2017)
for dev_index, val_index in kf.split(train_X):
dev_X, val_X = train_tfidf[dev_index], train_tfidf[val_index]
dev_y, val_y = train_y[dev_index], train_y[val_index]
pred_val_y, pred_test_y, model = runMNB(dev_X, dev_y, val_X, val_y, test_tfidf)
pred_full_test = pred_full_test + pred_test_y
pred_train[val_index,:] = pred_val_y
cv_scores.append(metrics.log_loss(val_y, pred_val_y))
print("Mean cv score : ", np.mean(cv_scores))
pred_full_test = pred_full_test / 5.Success is not guaranteed, but it is worth fighting for.
- Max Holloway -
'캐글' 카테고리의 다른 글
| [Kaggle Study] #14 Toxic Comment Classification Challenge (0) | 2024.12.04 |
|---|---|
| [Kaggle Study] #11 Credit Card Fraud Detection (0) | 2024.12.03 |
| [Kaggle Study] #10 Zillow Prize: Zillow’s Home Value Prediction (Zestimate) (0) | 2024.11.29 |
| [Kaggle Study] #9 New York City Taxi Trip Duration (0) | 2024.11.29 |
| [Kaggle Study] #8 2018 Data Science Bowl (0) | 2024.11.28 |