This post heavily relies on Will Koehrsen's public codes on Home Credit Default Risk Competition.
https://www.kaggle.com/code/willkoehrsen/start-here-a-gentle-introduction
https://www.kaggle.com/code/willkoehrsen/introduction-to-manual-feature-engineering
Above 2 posts are the first 2 public codes(kernels) on this competition written by Koehrsen and they are reviewed from my previous post:
[Kaggle Study] #3 Home Credit Default Risk
Third Competition following Yuhan Lee's kaggle curriculum. Binary classification competition using tabular data. First KernelGeneral EDA kernel. Insights/Summary:1. This kernel's eda was processed by this order:target column(binary var) analysisMissing
dongsunseng.com
Third Kernel: Introduction to Manual Feature Engineering P2
- We used the information from the bureau and bureau_balance from the previous kernel.
- Now we utilize information from previous_application, POS_CASH_balance, installments_payments, and credit_card_balance data files.
- Simply applying the same process of the previous kernel with new data.
Insight / Summary:
1. Definition of four additional data files:
- previous_application (called previous): previous applications for loans at Home Credit of clients who have loans in the application data. Each current loan in the application data can have multiple previous loans. Each previous application has one row and is identified by the feature SK_ID_PREV.
- POS_CASH_BALANCE (called cash): monthly data about previous point of sale or cash loans clients have had with Home Credit. Each row is one month of a previous point of sale or cash loan, and a single previous loan can have many rows.
- credit_card_balance (called credit): monthly data about previous credit cards clients have had with Home Credit. Each row is one month of a credit card balance, and a single credit card can have many rows.
- installments_payment (called installments): payment history for previous loans at Home Credit. There is one row for every made payment and one row for every missed payment.
2. Function to Convert Data Types
- This will help reduce memory usage by using more efficient types for the variables.
- For example category is often a better type than object (unless the number of unique categories is close to the number of rows in the dataframe).
import sys
def return_size(df):
"""Return size of dataframe in gigabytes"""
return round(sys.getsizeof(df) / 1e9, 2)
def convert_types(df, print_info = False):
original_memory = df.memory_usage().sum()
# Iterate through each column
for c in df:
# Convert ids and booleans to integers
if ('SK_ID' in c):
df[c] = df[c].fillna(0).astype(np.int32)
# Convert objects to category
elif (df[c].dtype == 'object') and (df[c].nunique() < df.shape[0]):
df[c] = df[c].astype('category')
# Booleans mapped to integers
elif list(df[c].unique()) == [1, 0]:
df[c] = df[c].astype(bool)
# Float64 to float32
elif df[c].dtype == float:
df[c] = df[c].astype(np.float32)
# Int64 to int32
elif df[c].dtype == int:
df[c] = df[c].astype(np.int32)
new_memory = df.memory_usage().sum()
if print_info:
print(f'Original Memory Usage: {round(original_memory / 1e9, 2)} gb.')
print(f'New Memory Usage: {round(new_memory / 1e9, 2)} gb.')
return dfFourth Kernel: Automated Feature Engineering Basics
- Applying automated feature engineering to the Home Credit Default Risk dataset using the featuretools library.
- Featuretools is an open-source Python package for automatically creating new features from multiple tables of structured, related data.
- It is ideal tool for problems such as the Home Credit Default Risk competition where there are several related tables that need to be combined into a single dataframe for training (and one for testing).
Insight / Summary:
1. About Feature Engineering
- The objective of feature engineering is to create new features (also called explanatory variables or predictors) to represent as much information from an entire dataset in one table.
- Typically, this process is done by hand using pandas operations such as groupby, agg, or merge and can be very tedious.
- Moreover, manual feature engineering is limited both by human time constraints and imagination: we simply cannot conceive of every possible feature that will be useful.
- The importance of creating the proper features cannot be overstated because a machine learning model can only learn from the data we give to it.
- Extracting as much information as possible from the available datasets is crucial to creating an effective solution.
- Automated feature engineering aims to help the data scientist with the problem of feature creation by automatically building hundreds or thousands of new features from a dataset.
- Featuretools - the only library for automated feature engineering at the moment - will not replace the data scientist, but it will allow her to focus on more valuable parts of the machine learning pipeline, such as delivering robust models into production.
- Here we will touch on the concepts of automated feature engineering with featuretools and show how to implement it for the Home Credit Default Risk competition.
- We will stick to the basics so we can get the ideas down and then build upon this foundation in later work when we customize featuretools.
- We will work with a subset of the data because this is a computationally intensive job that is outside the capabilities of the Kaggle kernels.
- I took the work done in this notebook and ran the methods on the entire dataset with the results available here.
- At the end of this notebook, we'll look at the features themselves, as well as the results of modeling with different combinations of hand designed and automatically built features.
2. Featuretools Basics
- Featuretools is an open-source Python library for automatically creating features out of a set of related tables using a technique called deep feature synthesis.
- Automated feature engineering, like many topics in machine learning, is a complex subject built upon a foundation of simpler ideas.
- Entities and EntitySets
- Relationships between tables
- Feature primitives: aggregations and transformations
- Deep feature synthesis
1) Entities and Entitysets
- An entity is simply a table or in Pandas, a dataframe.
- The observations are in the rows and the features in the columns.
- An entity in featuretools must have a unique index where none of the elements are duplicated.
- Currently, only app, bureau, and previous have unique indices (SK_ID_CURR, SK_ID_BUREAU, and SK_ID_PREV respectively).
- For the other dataframes, we must pass in make_index = True and then specify the name of the index.
- Entities can also have time indices where each entry is identified by a unique time.
- (There are not datetimes in any of the data, but there are relative times, given in months or days, that we could consider treating as time variables).
- An EntitySet is a collection of tables and the relationships between them.
- This can be thought of a data structute with its own methods and attributes.
- Using an EntitySet allows us to group together multiple tables and manipulate them much quicker than individual tables.
2) Relationships
- Relationships are a fundamental concept not only in featuretools, but in any relational database.
- The best way to think of a one-to-many relationship is with the analogy of parent-to-child.
- A parent is a single individual, but can have mutliple children.
- The children can then have multiple children of their own.
- In a parent table, each individual has a single row.
- Each individual in the parent table can have multiple rows in the child table.
- As an example, the app dataframe has one row for each client (SK_ID_CURR) while the bureau dataframe has multiple previous loans (SK_ID_PREV) for each parent (SK_ID_CURR).
- Therefore, the bureau dataframe is the child of the app dataframe.
- The bureau dataframe in turn is the parent of bureau_balance because each loan has one row in bureau but multiple monthly records in bureau_balance.
print('Parent: app, Parent Variable: SK_ID_CURR\n\n', app.iloc[:, 111:115].head())
print('\nChild: bureau, Child Variable: SK_ID_CURR\n\n', bureau.iloc[10:30, :4].head())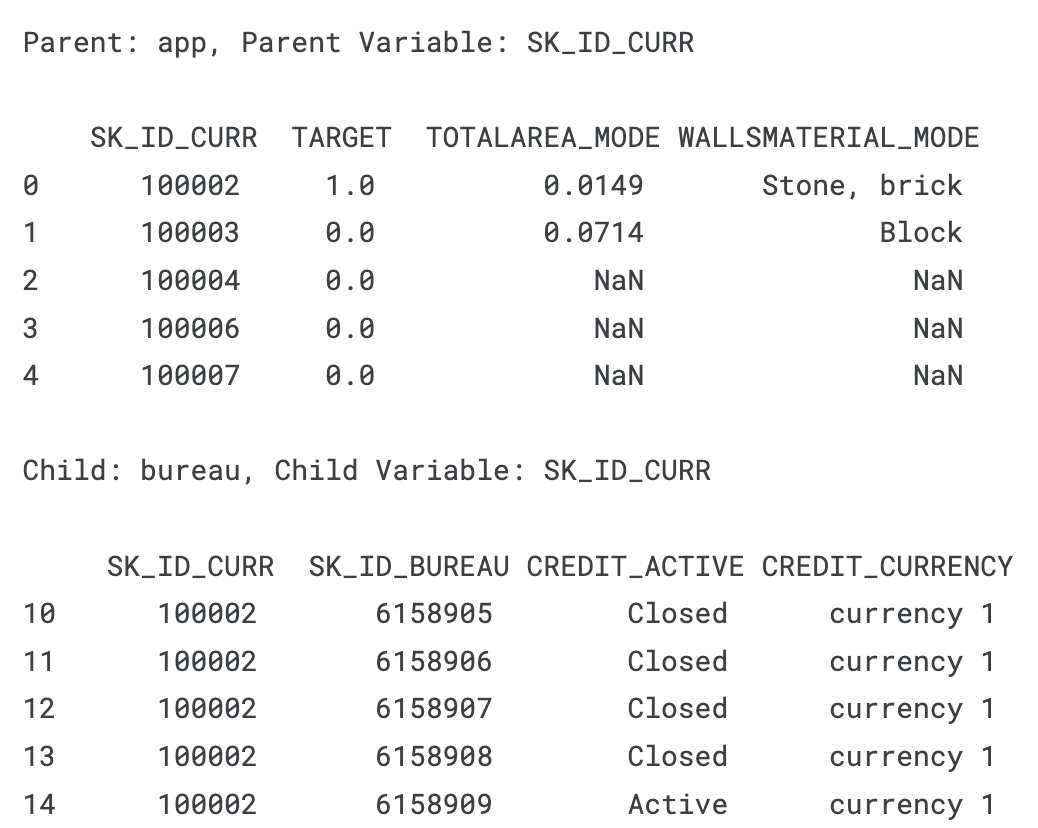
- The SK_ID_CURR "100002" has one row in the parent table and multiple rows in the child.
- Two tables are linked via a shared variable.
- The app and bureau dataframe are linked by the SK_ID_CURR variable while the bureau and bureau_balance dataframes are linked with the SK_ID_BUREAU.
- For each relationship, we need to specify the parent variable and the child variable.
- Altogether, there are a total of 6 relationships between the tables.
- Below we specify all six relationships and then add them to the EntitySet.
# Relationship between app and bureau
r_app_bureau = ft.Relationship(es['app']['SK_ID_CURR'], es['bureau']['SK_ID_CURR'])
# Relationship between bureau and bureau balance
r_bureau_balance = ft.Relationship(es['bureau']['SK_ID_BUREAU'], es['bureau_balance']['SK_ID_BUREAU'])
# Relationship between current app and previous apps
r_app_previous = ft.Relationship(es['app']['SK_ID_CURR'], es['previous']['SK_ID_CURR'])
# Relationships between previous apps and cash, installments, and credit
r_previous_cash = ft.Relationship(es['previous']['SK_ID_PREV'], es['cash']['SK_ID_PREV'])
r_previous_installments = ft.Relationship(es['previous']['SK_ID_PREV'], es['installments']['SK_ID_PREV'])
r_previous_credit = ft.Relationship(es['previous']['SK_ID_PREV'], es['credit']['SK_ID_PREV'])
# Add in the defined relationships
es = es.add_relationships([r_app_bureau, r_bureau_balance, r_app_previous,
r_previous_cash, r_previous_installments, r_previous_credit])
# Print out the EntitySet
es
- Slightly advanced note: we need to be careful not to create a diamond graph where there are multiple paths from a parent to a child.
- If we directly link app and cash via SK_ID_CURR; previous and cash via SK_ID_PREV; and app and previous via SK_ID_CURR, then we have created two paths from app to cash.
- This results in ambiguity, so the approach we have to take instead is to link app to cash through previous.
- We establish a relationship between previous (the parent) and cash (the child) using SK_ID_PREV.
- Then we establish a relationship between app (the parent) and previous (now the child) using SK_ID_CURR.
- Then featuretools will be able to create features on app derived from both previous and cash by stacking multiple primitives.
- All entities in the entity can be related to each other.
- In theory this allows us to calculate features for any of the entities, but in practice, we will only calculate features for the app dataframe since that will be used for training/testing.
3) Feature Primitives
- A feature primitive is an operation applied to a table or a set of tables to create a feature.
- These represent simple calculations, many of which we already use in manual feature engineering, that can be stacked on top of each other to create complex features.
- Feature primitives fall into two categories:
- Aggregation: function that groups together child datapoints for each parent and then calculates a statistic such as mean, min, max, or standard deviation. An example is calculating the maximum previous loan amount for each client. An aggregation works across multiple tables using relationships between tables.
- Transformation: an operation applied to one or more columns in a single table. An example would be taking the absolute value of a column, or finding the difference between two columns in one table.
4) Deep Feature Synthesis
- Deep Feature Synthesis (DFS) is the process featuretools uses to make new features.
- DFS stacks feature primitives to form features with a "depth" equal to the number of primitives.
- For example, if we take the maximum value of a client's previous loans (say MAX(previous.loan_amount)), that is a "deep feature" with a depth of 1.
- To create a feature with a depth of two, we could stack primitives by taking the maximum value of a client's average montly payments per previous loan (such as MAX(previous(MEAN(installments.payment)))).
- To perform DFS in featuretools, we use the dfs function passing it an entityset, the target_entity (where we want to make the features), the agg_primitives to use, the trans_primitives to use and the max_depth of the features.
- Here we will use the default aggregation and transformation primitives, a max depth of 2, and calculate primitives for the app entity.
- Because this process is computationally expensive, we can run the function using features_only = True to return only a list of the features and not calculate the features themselves.
- This can be useful to look at the resulting features before starting an extended computation.
# Default primitives from featuretools
default_agg_primitives = ["sum", "std", "max", "skew", "min", "mean", "count", "percent_true", "num_unique", "mode"]
default_trans_primitives = ["day", "year", "month", "weekday", "haversine", "numwords", "characters"]
# DFS with specified primitives
feature_names = ft.dfs(entityset = es, target_entity = 'app',
trans_primitives = default_trans_primitives,
agg_primitives=default_agg_primitives,
max_depth = 2, features_only=True)
print('%d Total Features' % len(feature_names))
# result: 1697 Total Features- Using a computer with 64GB of ram, this function call took around 24 hours.
DFS with Selected Aggregation Primitives
- With featuretools, we were able to go from 121 original features to almost 1700 in a few lines of code.
- When I did feature engineering by hand, it took about 12 hours to create a comparable size dataset.
- However, while we get a lot of features in featuretools, this function call is not very well-informed.
- We simply used the default aggregations without thinking about which ones are "important" for the problem.
- We end up with a lot of features, but they are probably not all relevant to the problem.
- Too many irrelevant features can decrease performance by drowning out the important features (related to the curse of dimensionality)
- The next call we make will specify a smaller set of features.
- We still are not using much domain knowledge, but this feature set will be more manageable.
- The next step from here is improving the features we actually build and performing feature selection.
# Specify the aggregation primitives
feature_matrix_spec, feature_names_spec = ft.dfs(entityset = es, target_entity = 'app',
agg_primitives = ['sum', 'count', 'min', 'max', 'mean', 'mode'],
max_depth = 2, features_only = False, verbose = True)
# result: Built 884 features- That "only" gives us 884 features (and takes about 12 hours to run on the complete dataset).
3. Notes on Basic Implementation
- These calls represent only a small fraction of the ability of featuretools.
- We did not specify the variable types when creating entities, did not use the relative time variables, and didn't touch on custom primitives or seed features or interesting values
4. Results:
- To determine whether our basic implementation of featuretools was useful, we can look at several results:
- Cross validation scores and public leaderboard scores using several different sets of features.
- Correlations: both between the features and the TARGET, and between features themselves
- Feature importances: determined by a gradient boosting machine model
Fifth Kernel: Tuning Automated Feature Engineering (Exploratory)
- Explore a few different methods for improving the set of features and incorporating domain knowledge into the final dataset. These methods include:
- Properly representing variable types
- Creating and using time variables
- Setting interesting values of variables
- Creating seed features
- Building custom primitives
Insight / Summary:
1. Properly Representing Variable Types
- There are a number of columns in the app dataframe that are represented as integers but are really discrete variables that can only take on a limited number of features.
- Some of these are Boolean flags (only 1 or 0) and two columns are ordinal (ordered discrete).
- To tell featuretools to treat these as Boolean variables, we need to pass in the correct datatype using a dictionary mapping {variable_name: variable_type}.
app_types = {}
# Iterate through the columns and record the Boolean columns
for col in app_train:
# If column is a number with only two values, encode it as a Boolean
if (app_train[col].dtype != 'object') and (len(app_train[col].unique()) <= 2):
app_types[col] = ft.variable_types.Boolean
print('Number of boolean variables: ', len(app_types))
# result: Number of boolean variables: 33
# Record ordinal variables
app_types['REGION_RATING_CLIENT'] = ft.variable_types.Ordinal
app_types['REGION_RATING_CLIENT_W_CITY'] = ft.variable_types.Ordinal
app_test_types = app_types.copy()
del app_test_types['TARGET']
# Record boolean variables in the previous data
previous_types= {'NFLAG_LAST_APPL_IN_DAY': ft.variable_types.Boolean,
'NFLAG_INSURED_ON_APPROVAL': ft.variable_types.Boolean}
2. Time Variables
- Time can be a crucial factor in many datasets because behaviors change over time and therefore we want to make features to reflect this.
- For example, a client might be taking out larger and larger loans over time which could be an indicator that they are about to default or they could have a run of missed payments but then get back on track.
- There are no explicit datetimes in the data, but there are relative time offsets.
- All the time offset are measured from the current application at Home Credit and are measured in months or days.
- For example, in bureau, the DAYS_CREDIT column represents "How many days before current application did client apply for Credit Bureau credit". (Credit Bureau refers to any other credit organization besides Home Credit).
- Although we do not know the actual application date, if we assume a starting application date that is the same for all clients, then we can convert the MONTHS_BALANCE into a datetime.
- This can then be treated as a relative time that we can use to find trends or identify the most recent value of a variable.
Example with Bureau data:
1. Replace Outliers
import re
def replace_day_outliers(df):
"""Replace 365243 with np.nan in any columns with DAYS"""
for col in df.columns:
if "DAYS" in col:
df[col] = df[col].replace({365243: np.nan})
return df
# Replace all the day outliers
app_train = replace_day_outliers(app_train)
app_test = replace_day_outliers(app_test)
bureau = replace_day_outliers(bureau)
bureau_balance = replace_day_outliers(bureau_balance)
credit = replace_day_outliers(credit)
cash = replace_day_outliers(cash)
previous = replace_day_outliers(previous)
installments = replace_day_outliers(installments)2. Establish an arbitrary date
# Establish a starting date for all applications at Home Credit
start_date = pd.Timestamp("2016-01-01")
start_date
# result: Timestamp('2016-01-01 00:00:00')3. Convert the time offset in months into a Pandas timedelta object
# Convert to timedelta in days
for col in ['DAYS_CREDIT', 'DAYS_CREDIT_ENDDATE', 'DAYS_ENDDATE_FACT', 'DAYS_CREDIT_UPDATE']:
bureau[col] = pd.to_timedelta(bureau[col], 'D')
bureau[['DAYS_CREDIT', 'DAYS_CREDIT_ENDDATE', 'DAYS_ENDDATE_FACT', 'DAYS_CREDIT_UPDATE']].head()- These four columns represent different offsets:
- DAYS_CREDIT: Number of days before current application at Home Credit client applied for loan at other financial institution. We will call this the application date, bureau_credit_application_date and make it the time_index of the entity.
- DAYS_CREDIT_ENDDATE: Number of days of credit remaining at time of client's application at Home Credit. We will call this the ending date, bureau_credit_end_date
- DAYS_ENDDATE_FACT: For closed credits, the number of days before current application at Home Credit that credit at other financial institution ended. We will call this the closing date, bureau_credit_close_date.
- DAYS_CREDIT_UPDATE: Number of days before current application at Home Credit that the most recent information about the previous credit arrived. We will call this the update date, bureau_credit_update_date.
- If we were doing manual feature engineering, we might want to create new columns such as by subtracting DAYS_CREDIT_ENDDATE from DAYS_CREDIT to get the planned length of the loan in days, or subtracting DAYS_CREDIT_ENDDATE from DAYS_ENDDATE_FACT to find the number of days the client paid off the loan early.
- However, we will not make any features by hand, but rather let featuretools develop useful features for us.
4. To make date columns from the timedelta, we simply add the offset to the start date
# Create the date columns
bureau['bureau_credit_application_date'] = start_date + bureau['DAYS_CREDIT']
bureau['bureau_credit_end_date'] = start_date + bureau['DAYS_CREDIT_ENDDATE']
bureau['bureau_credit_close_date'] = start_date + bureau['DAYS_ENDDATE_FACT']
bureau['bureau_credit_update_date'] = start_date + bureau['DAYS_CREDIT_UPDATE']5. Applying Featuretools
- Let's look at some of the time features we can make from the new time variables.
- Because these times are relative and not absolute, we are only interested in values that show change over time, such as trend or cumulative sum.
- We would not want to calculate values like the year or month since we choose an arbitrary starting date.
- Throughout this notebook, we will pass in a chunk_size to the dfs call which specifies the number of rows (if an integer) or the fraction or rows to use in each chunk (if a float).
- This can help to optimize the dfs procedure, and the chunk_size can have a significant effect on the run time.
- Here we will use a chunk size equal to the number of rows in the data so all the results will be calculated in one pass.
- We also want to avoid making any features with the testing data, so we pass in ignore_entities = [app_test].
time_features, time_feature_names = ft.dfs(entityset = es, target_entity = 'app_train',
trans_primitives = ['cum_sum', 'time_since_previous'], max_depth = 2,
agg_primitives = ['trend'] ,
features_only = False, verbose = True,
chunk_size = len(app_train),
ignore_entities = ['app_test'])6. Interesting Values
- Another method we can use in featuretools is "interesting values."
- Specifying interesting values will calculate new features conditioned on values of existing features.
- For example, we can create new features that are conditioned on the value of NAME_CONTRACT_STATUS in the previous dataframe.
- Each stat will be calculated for the specified interesting values which can be useful when we know that there are certain indicators that are of greater importance in the data.
- To use interesting values, we assign them to the variable and then specify the where_primitives in the dfs call.
# Assign interesting values
es['previous']['NAME_CONTRACT_STATUS'].interesting_values = ['Approved', 'Refused', 'Canceled']
# Calculate the features with intereseting values
interesting_features, interesting_feature_names = ft.dfs(entityset=es, target_entity='app_train', max_depth = 1,
where_primitives = ['mean', 'mode'],
trans_primitives=[], features_only = False, verbose = True,
chunk_size = len(app_train),
ignore_entities = ['app_test'])- Based on the most important features returned by a model, we can create new interesting features. This is one area where we can apply domain knowledge to feature creation.
7. Seed Features
- An additional extension to the default aggregations and transformations is to use seed features.
- These are user defined features that we provide to deep feature synthesis that can then be built on top of where possible.
- As an example, we can create a seed feature that determines whether or not a payment was late. This time when we make the dfs function call, we need to pass in the seed_features argument.
# Late Payment seed feature
late_payment = ft.Feature(es['installments']['installments_due_date']) < ft.Feature(es['installments']['installments_paid_date'])
# Rename the feature
late_payment = late_payment.rename("late_payment")
# DFS with seed features
seed_features, seed_feature_names = ft.dfs(entityset = es,
target_entity = 'app_train',
agg_primitives = ['percent_true', 'mean'],
trans_primitives = [],
seed_features = [late_payment],
features_only = False, verbose = True,
chunk_size = len(app_train),
ignore_entities = ['app_test'])8. Create Custom Feature Primitives
- If we are not satisfied with the existing primitives in featuretools, we can write our own.
- This is an extremely powerful method that lets us expand the capabilities of featuretools.
- NormalizedModeCount and LongestSeq
- As an example, we will make three features.
- These will be aggregation primitives, where the function takes in an array of values and returns a single value.
- The first, NormalizedModeCount, builds upon the Mode function by returning the fraction of total observations in a categorical feature that the model makes up.
- In other words, for a client with 5 total bureau_balance observations where 4 of the STATUS were X, the value of the NormalizedModeCount would be 0.8.
- The idea is to record not only the most common value, but also the relative frequency of the most common value compared to all observations.
- The second custom feature will record the longest consecutive run of a discrete variable.
- LongestSeq takes in an array of discrete values and returns the element that appears the most consecutive times.
- Because entities in the entityset are sorted by the time_index, this will return the value that occurs the most number of times in a row with respect to time.
from featuretools.variable_types import (
Boolean, Datetime,
DatetimeTimeIndex,
Discrete,
Index,
Numeric,
Variable,
Id
)
from featuretools.primitives import AggregationPrimitive, make_agg_primitive
from datetime import datetime, timedelta
from collections import Counter
def normalized_mode_count(x):
"""
Return the fraction of total observations that
are the most common observation. For example,
in an array of ['A', 'A', 'A', 'B', 'B'], the
function will return 0.6."""
if x.mode().shape[0] == 0:
return np.nan
# Count occurence of each value
counts = dict(Counter(x.values))
# Find the mode
mode = x.mode().iloc[0]
# Divide the occurences of mode by the total occurrences
return counts[mode] / np.sum(list(counts.values()))
NormalizedModeCount = make_agg_primitive(function = normalized_mode_count,
input_types = [Discrete],
return_type = Numeric)
# Function from https://codereview.stackexchange.com/a/15095
def longest_repetition(x):
"""
Returns the item with most consecutive occurrences in `x`.
If there are multiple items with the same number of conseqcutive occurrences,
it will return the first one. If `x` is empty, returns None.
"""
x = x.dropna()
if x.shape[0] < 1:
return None
# Set the longest element
longest_element = current_element = None
longest_repeats = current_repeats = 0
# Iterate through the iterable
for element in x:
if current_element == element:
current_repeats += 1
else:
current_element = element
current_repeats = 1
if current_repeats > longest_repeats:
longest_repeats = current_repeats
longest_element = current_element
return longest_element
LongestSeq = make_agg_primitive(function = longest_repetition,
input_types = [Discrete],
return_type = Discrete)# DFS with custom features
custom_features, custom_feature_names = ft.dfs(entityset = es,
target_entity = 'app_train',
agg_primitives = [NormalizedModeCount, LongestSeq],
max_depth = 2,
trans_primitives = [],
features_only = False, verbose = True,
chunk_size = len(app_train),
ignore_entities = ['app_test'])
custom_features.iloc[:, -40:].head()- MostRecent
- The final custom feature will be MOSTRECENT.
- This simply returns the most recent value of a discrete variable with respect to time columns in a dataframe.
- When we create an entity, featuretools will sort the entity by the time_index.
- Therefore, the built-in aggregation primitive LAST calculates the most recent value based on the time index.
- However, in cases where there are multiple different time columns, it might be useful to know the most recent value with respect to all of the times.
- To build the custom feature primitive, I adapted the existing TREND primitive.
# Building on the Trend Aggregation Primitive
# Copied from https://github.com/Featuretools/featuretools/blob/master/featuretools/primitives/aggregation_primitives.py
def most_recent(y, x):
df = pd.DataFrame({"x": x, "y": y}).dropna()
if df.shape[0] < 1:
return np.nan
# Sort the values by timestamps reversed
df = df.sort_values('x', ascending = False).reset_index()
# Return the most recent occurence
return df.iloc[0]['y']
MostRecent = make_agg_primitive(function = most_recent,
input_types = [Discrete, Datetime],
return_type = Discrete)- In this notebook we explored some of the advanced functionality in featuretools including:
- Time Variables: allow us to track trends over time
- Interesting Variables: condition new features on values of existing features
- Seed Features: define new features manually that featuretools will then build on top of
- Custom feature primitives: design any transformation or aggregation feature that can incorporate domain knowledge
- We can use these methods to encode domain knowledge about a problem into our features or create features based on what others have found useful. The next step from here would be to run the script on the entire dataset, then use the features for modeling. We could use the feature importances from the model to determine the most relevant features, perform feature selection, and then go through another round of feature synthesis with a new set of of primitives, seed features, and interesting features. As with many aspects of machine learning, feature creation is largely an empirical and iterative procedure.
Sixth Kernel: Introduction to Feature Selection
- Mainly about Feature Selection methodologies.
- Remove collinear features
- Remove features with greater than a threshold percentage of missing values
- Keep only the most relevant features using feature importances from a model
Insight / Summary:
1. Remove collinear features
- Collinear variables are those which are highly correlated with one another.
- These can decrease the model's availablility to learn, decrease model interpretability, and decrease generalization performance on the test set.
- Clearly, these are three things we want to increase, so removing collinear variables is a useful step.
- We will establish an admittedly arbitrary threshold for removing collinear variables, and then remove one out of any pair of variables that is above that threshold.
- The code below identifies the highly correlated variables based on the absolute magnitude of the Pearson correlation coefficient being greater than 0.9.
# Threshold for removing correlated variables
threshold = 0.9
# Absolute value correlation matrix
corr_matrix = train.corr().abs()
corr_matrix.head()
# Upper triangle of correlations
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
upper.head()
# Select columns with correlations above threshold
to_drop = [column for column in upper.columns if any(upper[column] > threshold)]
print('There are %d columns to remove.' % (len(to_drop)))
#result: There are 584 columns to remove.train = train.drop(columns = to_drop)
test = test.drop(columns = to_drop)
print('Training shape: ', train.shape)
print('Testing shape: ', test.shape)
# Training shape: (1000, 814)
# Testing shape: (1000, 814)- Applying this on the entire dataset results in 538 collinear features removed.
- This has reduced the number of features singificantly, but it is likely still too many.
2. Remove Missing Values
- A relatively simple choice of feature selection is removing missing values.
- Well, it seems simple, at least until we have to decide what percentage of missing values is the minimum threshold for removing a column.
- Like many choices in machine learning, there is no right answer, and not even a general rule of thumb for making this choice.
- In this implementation, if any columns have greater than 75% missing values, they will be removed.
- Most models (including those in Sk-Learn) cannot handle missing values, so we will have to fill these in before machine learning.
- The Gradient Boosting Machine (at least in LightGBM) can handle missing values.
- Imputing missing values always makes me a little uncomfortable because we are adding information that actually isn't in the dataset.
- Since we are going to be evaluating several models (in a later notebook), we will have to use some form of imputation.
- For now, we will focus on removing columns above the threshold.
# Train missing values (in percent)
train_missing = (train.isnull().sum() / len(train)).sort_values(ascending = False)
train_missing.head()
# Test missing values (in percent)
test_missing = (test.isnull().sum() / len(test)).sort_values(ascending = False)
test_missing.head()
# Identify missing values above threshold
train_missing = train_missing.index[train_missing > 0.75]
test_missing = test_missing.index[test_missing > 0.75]
all_missing = list(set(set(train_missing) | set(test_missing)))
print('There are %d columns with more than 75%% missing values' % len(all_missing))
# result: There are 19 columns with more than 75% missing values# Need to save the labels because aligning will remove this column
train_labels = train["TARGET"]
train_ids = train['SK_ID_CURR']
test_ids = test['SK_ID_CURR']
train = pd.get_dummies(train.drop(columns = all_missing))
test = pd.get_dummies(test.drop(columns = all_missing))
train, test = train.align(test, join = 'inner', axis = 1)
print('Training set full shape: ', train.shape)
print('Testing set full shape: ' , test.shape)
train = train.drop(columns = ['SK_ID_CURR'])
test = test.drop(columns = ['SK_ID_CURR'])
3. Feature Selection through Feature Importances
- The next method we can employ for feature selection is to use the feature importances of a model.
- Tree-based models (and consequently ensembles of trees) can determine an "importance" for each feature by measuring the reduction in impurity for including the feature in the model.
- The absolute value of the importance can be difficult to interpret.
- However, the relative value of the importances can be used as an approximation of the "relevance" of different features in a model.
- Moreover, we can use the feature importances to remove features that the model does not consider important.
- One method for doing this automatically is the Recursive Feature Elimination method in Scikit-Learn.
- This accepts an estimator (one that either returns feature weights such as a linear regression, or feature importances such as a random forest) and a desired number of features.
- In then fits the model repeatedly on the data and iteratively removes the lowest importance features until the desired number of features is left.
- This means we have another arbitrary hyperparameter to use in out pipeline: the number of features to keep
- Instead of doing this automatically, we can perform our own feature removal by first removing all zero importance features from the model.
- If this leaves too many features, then we can consider removing the features with the lowest importance.
- We will use a Gradient Boosted Model from the LightGBM library to assess feature importances.
- If you're used to the Scikit-Learn library, the LightGBM library has an API that makes deploying the model very similar to using a Scikit-Learn model.
- Since the LightGBM model does not need missing values to be imputed, we can directly fit on the training data.
- We will use Early Stopping to determine the optimal number of iterations and run the model twice, averaging the feature importances to try and avoid overfitting to a certain set of features.
# Initialize an empty array to hold feature importances
feature_importances = np.zeros(train.shape[1])
# Create the model with several hyperparameters
model = lgb.LGBMClassifier(objective='binary', boosting_type = 'goss', n_estimators = 10000, class_weight = 'balanced')
# Fit the model twice to avoid overfitting
for i in range(2):
# Split into training and validation set
train_features, valid_features, train_y, valid_y = train_test_split(train, train_labels, test_size = 0.25, random_state = i)
# Train using early stopping
model.fit(train_features, train_y, early_stopping_rounds=100, eval_set = [(valid_features, valid_y)],
eval_metric = 'auc', verbose = 200)
# Record the feature importances
feature_importances += model.feature_importances_# Make sure to average feature importances!
feature_importances = feature_importances / 2
feature_importances = pd.DataFrame({'feature': list(train.columns), 'importance': feature_importances}).sort_values('importance', ascending = False)
feature_importances.head()# Find the features with zero importance
zero_features = list(feature_importances[feature_importances['importance'] == 0.0]['feature'])
print('There are %d features with 0.0 importance' % len(zero_features))
feature_importances.tail()# Remove the features that have zero importance
train = train.drop(columns = zero_features)
test = test.drop(columns = zero_features)
print('Training shape: ', train.shape)
print('Testing shape: ', test.shape)- Checking how many features are needed to achieve a specific cumulative importance is a useful method when determining the number of features to use.

def plot_feature_importances(df, threshold = 0.9):
"""
Plots 15 most important features and the cumulative importance of features.
Prints the number of features needed to reach threshold cumulative importance.
Parameters
--------
df : dataframe
Dataframe of feature importances. Columns must be feature and importance
threshold : float, default = 0.9
Threshold for prining information about cumulative importances
Return
--------
df : dataframe
Dataframe ordered by feature importances with a normalized column (sums to 1)
and a cumulative importance column
"""
plt.rcParams['font.size'] = 18
# Sort features according to importance
df = df.sort_values('importance', ascending = False).reset_index()
# Normalize the feature importances to add up to one
df['importance_normalized'] = df['importance'] / df['importance'].sum()
df['cumulative_importance'] = np.cumsum(df['importance_normalized'])
# Make a horizontal bar chart of feature importances
plt.figure(figsize = (10, 6))
ax = plt.subplot()
# Need to reverse the index to plot most important on top
ax.barh(list(reversed(list(df.index[:15]))),
df['importance_normalized'].head(15),
align = 'center', edgecolor = 'k')
# Set the yticks and labels
ax.set_yticks(list(reversed(list(df.index[:15]))))
ax.set_yticklabels(df['feature'].head(15))
# Plot labeling
plt.xlabel('Normalized Importance'); plt.title('Feature Importances')
plt.show()
# Cumulative importance plot
plt.figure(figsize = (8, 6))
plt.plot(list(range(len(df))), df['cumulative_importance'], 'r-')
plt.xlabel('Number of Features'); plt.ylabel('Cumulative Importance');
plt.title('Cumulative Feature Importance');
plt.show();
importance_index = np.min(np.where(df['cumulative_importance'] > threshold))
print('%d features required for %0.2f of cumulative importance' % (importance_index + 1, threshold))
return df4. Other Options for Dimensionality Reduction
- We only covered a small portion of the techniques used for feature selection/dimensionality reduction. There are many other methods such as:
- PCA: Principle Components Analysis (PCA)
- ICA: Independent Components Analysis (ICA)
- Manifold learning: also called non-linear dimensionality reduction
- PCA is a great method for reducing the number of features provided that you do not care about model interpretability.
- It projects the original set of features onto a lower dimension, in the process, eliminating any physical representation behind the features.
- PCA assumes that the data is Gaussian distributed, which may not be the case, especially when dealing with real-world human generated data.
- ICA representations obscure any physical meaning behind the variables and presevere the most "independent" dimensions of the data (which is different than the dimensions with the most variance).
- Manifold learning is more often used for low-dimensional visualizations (such as with T-SNE or LLE) rather than for dimensionality reduction for a classifier.
- These methods are heavily dependent on several hyperparameters and are not deterministic which means that there is no way to apply it to new data (in other words you cannot fit it to the training data and then separately transform the testing data).
- The learned representation of a dataset will change every time you apply manifold learning so it is not generally a stable method for feature selection.
Seek inspiration from within, for that is where your true potential lies.
- Max Holloway -
'캐글' 카테고리의 다른 글
| [Kaggle Study] #6 Costa Rican Household Poverty Level Prediction (1) | 2024.11.28 |
|---|---|
| [Kaggle Study] #7 TensorFlow Speech Recognition Challenge (0) | 2024.11.27 |
| [Kaggle Study] #5 Statoil/C-CORE Iceberg Classifier Challenge (0) | 2024.11.25 |
| [Kaggle Study] #3 Home Credit Default Risk (0) | 2024.11.24 |
| [Kaggle Study] 17. ResNet Skip Connection (0) | 2024.11.22 |