Before we begin with the plots, you can find detailed information about data imputation from previous post:
[Kaggle Extra Study] 7. Data Imputation
While training machine learning models, it is necessary to preprocess missing values because it might greatly affect the performance of the model. Accordingly, there are various methods to deal with those missing values. Types of Missing Values:Missing co
dongsunseng.com
Detecting missing data visually using Missingno Library
Missingno is a library useful for analyzing missing data from graphical figures.
import missingno as msno
# plotting bar graph
msno.bar(train)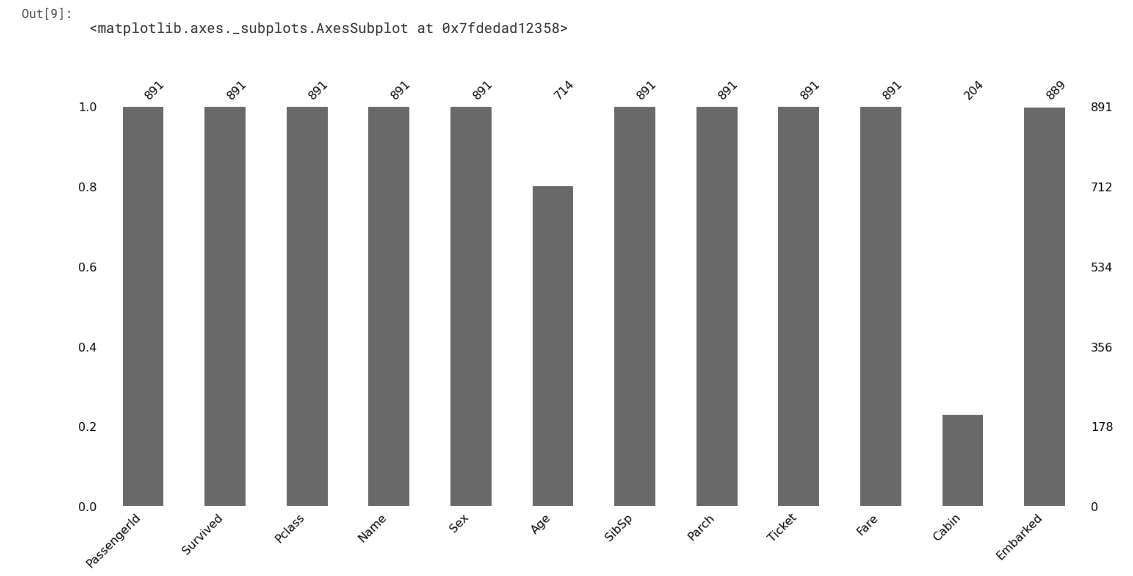
- Gives a quick graphical overview of the completeness of the dataset.
- Age, Cabin, and Embarked columns have missing values.
Visualizing the locations of the missing data
msno.matrix nullity matrix is a data-dense display that lets us visually identify patterns in data completion.
msno.matrix(train)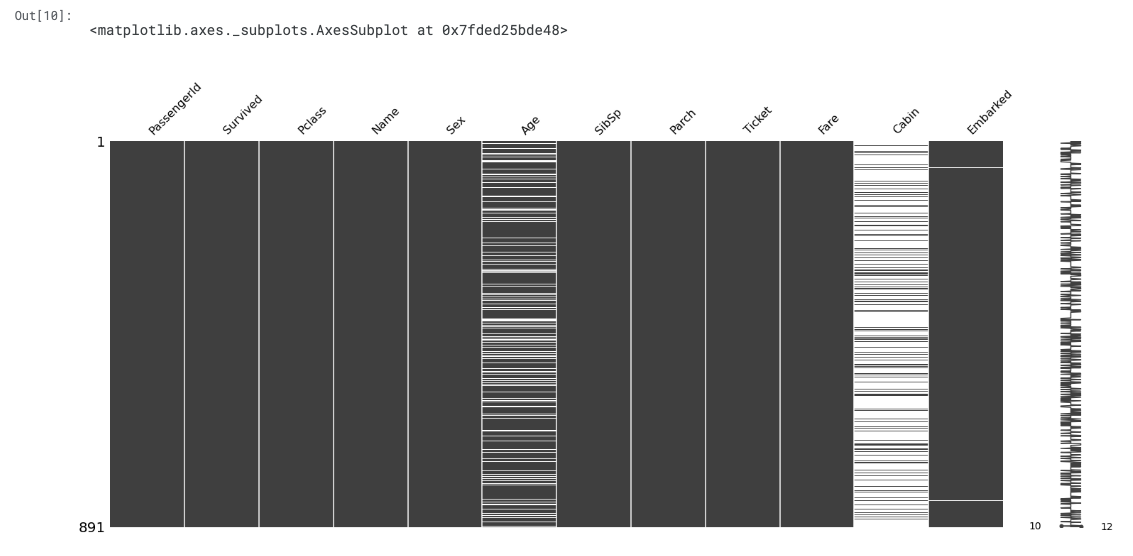
- The plot appears blank(white) wherever there are missing values.
- The sparkline on the right gives an idea of the general shape of the completeness of the data and points out the row with the minimum nullities and the total number of columns in a given dataset, at the bottom.
Sampling first 100 rows
msno.matrix(train.sample(100))Reasons for Missing Values
There are 3 types of missing values: MCAR, MAR, and NMAR. It is always clear to find out the reason for missing values before applying imputation techniques.
Example:
- Embarked column has very few missing values and do not seem to be correlated with any other column.
- Thus, the missingness in Embarked column can be attributed as Missing Completely at Random(MCAR).
- Both Age and Cabin columns have a lot of missing values.
- This could be a case of MAR as we cannot directly observe the reason for missingness of data in these columns.
Sorting particular columns
#sorted by Age
sorted = train.sort_values('Age')
msno.matrix(sorted)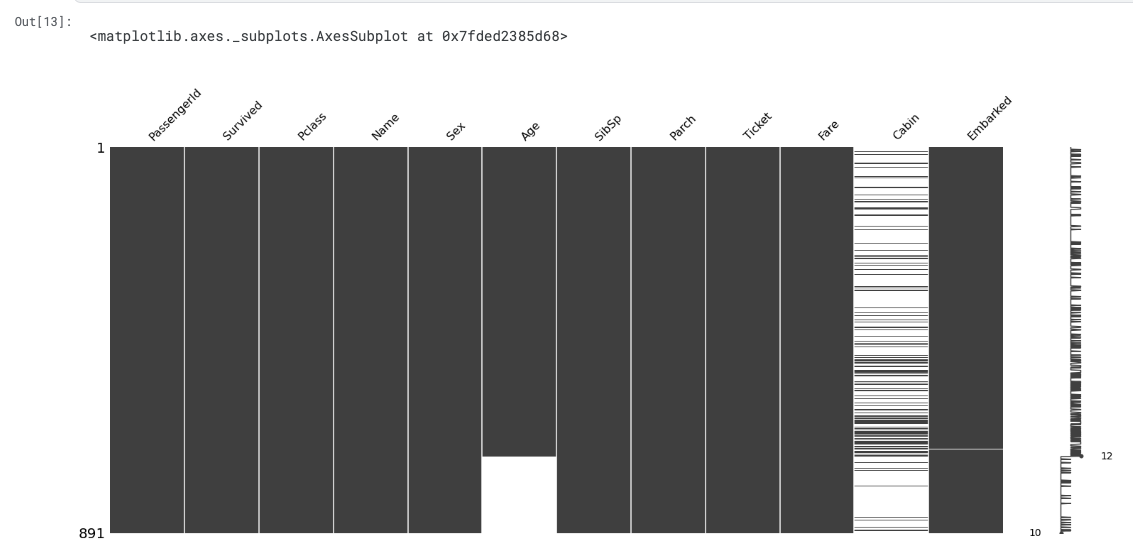
- It is evident that there is no relation between the missingness in Age and Cabin column.
- Before sorting Age column, it shows scattered white lines(missing values).
- The Cabin column is mostly white, indicating a large number of missing values.
- However, it shows similar scattered white lines even when data is sorted by Age column.
- The pattern of missing values in Age doesn't correspond with the missing values in Cabin.
- This means that passengers with known Ages don't necessarily have Cabin information.
- Similarly, passengers with missing ages don't necessarily have missing Cabin information.
- The missing values in these two columns occurred independently.
- The presence of absence of Age information did not influence whether Cabin information was recorded.
- This suggests that the data follows either a Missing at Random(MAR) or Missing Completely at Random(MCAR) pattern.
- We can also utilize heatmap and other plots to see the details.
Heatmap
msno.heatmap(train)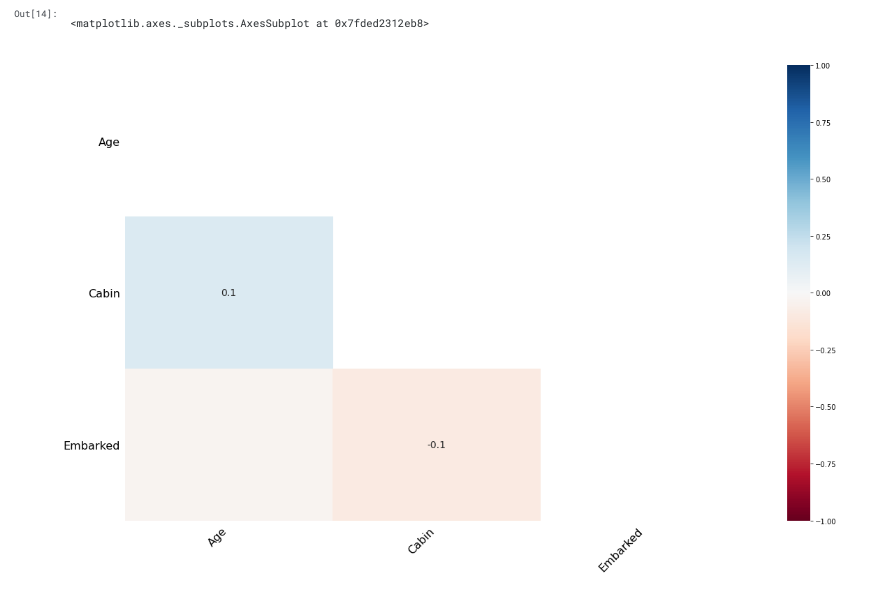
- Heatmap also verifies that there are no strong correlation between missing values of different features.
- This is good news because low correlations indicate that the data are MAR.
Dendrogram
Dendrogram is a tree diagram of missingness that groups highly correlated variables together.
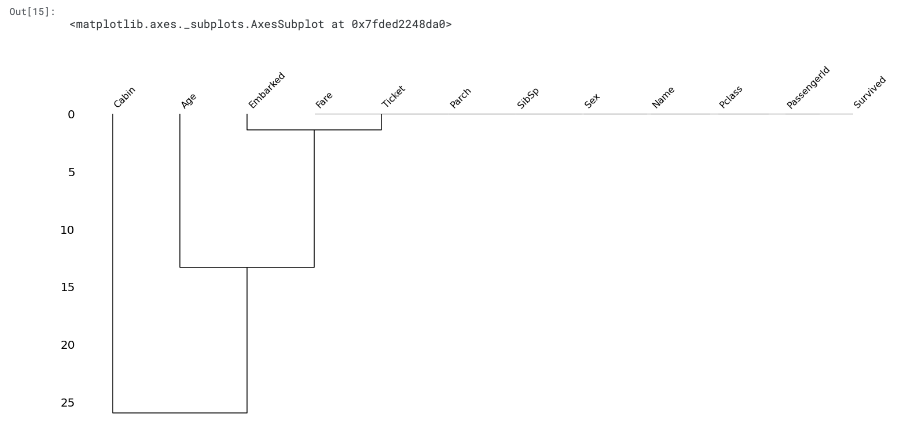
- Cluster leaves which linked together at a distance of zero fully predict one another's presence - one variable might always be empty when another is filled, or they might always both be filled or both empty, and so on.
- The missingness of Embarked tends to be more similar to Age than to Cabin and so on.
- However, in this particular case, the correlation is high since Embarked column has a very few missing values.
Why is it important to understand the various reasons for the missingness in data
- The reason for missingness helps determine the best imputation strategy
- MCAR: Simple methods like mean imputation might be acceptable
- MAR: More sophisticated methods like multiple imputation might be needed
- NMAR: May require special modeling approaches or additional data collection
- Different types of missingness can introduce different biases into your analysis
- Understanding missingness patterns helps assess reliability of the conclusion
However, it is always best to try out different methods to achieve the best performance.
Reference
A Guide to Handling Missing values in Python
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
Don't be afraid to take risks. It's in those moments of discomfort that you truly grow.
- Max Holloway -
'캐글' 카테고리의 다른 글
| [Kaggle Study] 3. Learning Rate (2) | 2024.10.29 |
|---|---|
| [Kaggle Study] 2. Scale of Features (1) | 2024.10.29 |
| [Kaggle Extra Study] 8. Imputation Techniques for Time Series Data (0) | 2024.10.27 |
| [Kaggle Study] Code CheatSheet (0) | 2024.10.27 |
| [Kaggle Extra Study] 7. Data Imputation (3) | 2024.10.27 |