반응형
CIBMTR - Equity in post-HCT Survival Predictions #11 ESP EDA which makes sense ⭐️⭐️⭐️⭐️⭐️ (AFT Loss func sol
Annotation post about AFT loss function solution:https://www.kaggle.com/code/ambrosm/esp-eda-which-makes-sense ESP EDA which makes sense ⭐️⭐️⭐️⭐️⭐️Explore and run machine learning code with Kaggle Notebooks | Using data from CIBMTR - E
dongsunseng.com
From my other blog post, we discussed about
This blog is about the "further discussion": https://www.kaggle.com/competitions/equity-post-HCT-survival-predictions/discussion/550302
CIBMTR - Equity in post-HCT Survival Predictions
Improve prediction of transplant survival rates equitably for allogeneic HCT patients
www.kaggle.com
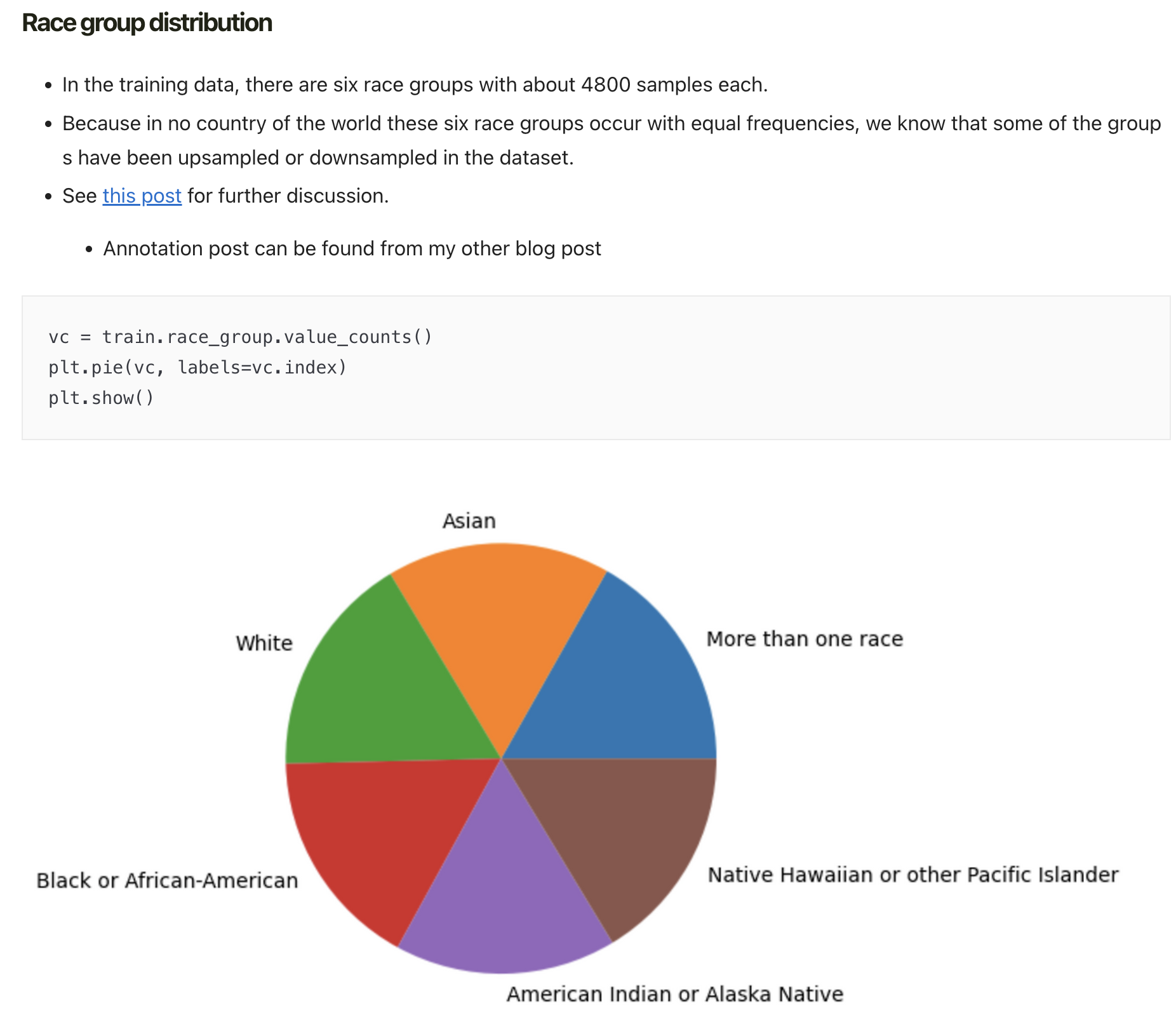
How to make sense of the race group distribution in the data ?
Counting values of race groups I get the following:

- Having worked on the topic of equity for sensitive applications, I have found one of the main problem to be imbalance in data of interest.
- Typically some less represented races will end up with wider estimates.
- However the data at hand seems to have been resampled (or generated as balanced).
- While this can be achieved on real data by downsampling the majority class, it usually kills representativeness of the population.
- I am concerned a model optimised with this metric on this balanced dataset would perform worse on real life 'race imbalanced' data.
- How does 'race-balancing' the dataset make sense in an equity competition ?
Comments:
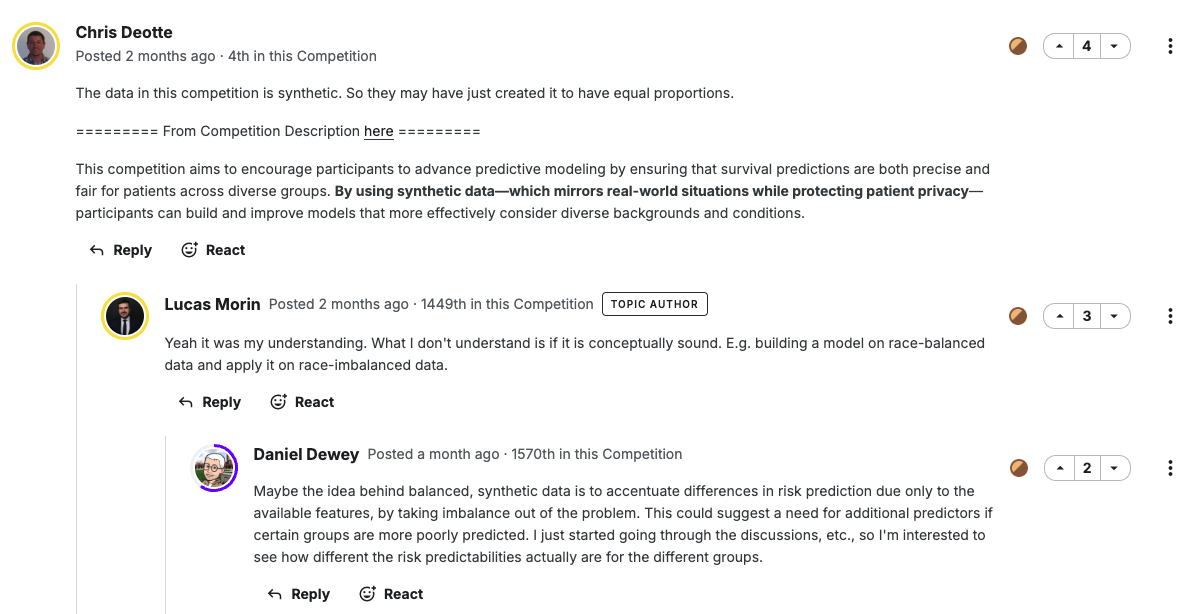
- Maybe the idea behind balanced, synthetic data is to accentuate differences in risk prediction due only to the available features, by taking imbalance out of the problem.
- By eliminating racial imbalances in the actual data, one can more clearly see differences in risk predictions that are "purely attributable to available features"
- This allows for more accurate evaluation of actual prediction performance differences rather than differences in population ratios
- This could suggest a need for additional predictors if certain groups are more poorly predicted.
- If predictions are less accurate for certain groups, this could indicate that current features don't adequately explain those groups
- This could signal the need for additional predictors that better characterize these groups
완벽하려고 미루는 것보다 지속적으로 고쳐나가는 것이 낫습니다.
- 마크 트웨인 -
반응형